



云服务3.0
APICloud云服务3.0
云服务3.0概述
数据云3.0是一个全新的服务端开发运维平台,提供从后端开发、接口联调到上线运营维护等一整套方案。开发者无需考虑数据库和服务器等基础设施,无需关心服务器测试环境的搭建,数据的备份及服务扩容等与业务无关的工作,只需关心逻辑本身。通过云引擎,云数据库,云函数,内置模型、等功能模块方便用户快速实现常用的后端功能。通过模型库复用快速把常用第三方功能引入到自己的项目中,极大缩短了开发时间。同时内置了管理后台、API调试等功能,在增加了用户自己编写后端服务的灵活性的同时方便了前后端开发者的联调和测试。在安全层面,我们也提供了接口层相应的安全校验机制。为了在新功能的迭代过程中不影响线上用户,我们提供了开发环境和测试环境,用户可以放心的把测试过的功能提供出去。针对已经开发好的功能模块,新版数据云可以直接把模块的定义及函数集成到项目中,方便开发者的使用。 新版的数据云可以实现很多后端常见的场景,例如:
- 一个小程序可以在APICloud上存储数据并通过自定义接口实现自己的业务逻辑.
- 一个移动app应用可以直接基于我们的云平台提供的能力完成后端工作。
- 一个网站可以展示来自APICloud上的数据,网站的前端也可以放到APICloud平台.
- 快速开发出项目最小化可行产品来验证市场
- 企业内部数字化业务的快速落地
API 版本
3.0 版本:2020年5月15日发布。
核心概念
Model:即数据模型,可以理解为一个数据结构,该数据结构直接映射到数据库的表中。在定义模型的同时,我们会为该模型自动提供相关的增删改查的远程接口,方便开发者直接使用。
云函数:在Model上定义的一些方法,可以用来操作Model上的数据,也可以实现特定功能的业务逻辑。云函数可以进一步分为远程函数、钩子函数、以及本地函数,具体使用详见下边的相关介绍。
运行环境:用户写好的服务运行在我们提供的虚拟服务器中,分为测试环境和正式环境。在开发调试阶段,使用测试环境不会影响正式环境的运行。这样,新的功能点可以无顾虑的在测试环境中进行。当功能通过测试后可以正式发布到正式环境。 正式环境的docker会持续运行。所以如果开发者完成开发工作后要线上运营相关项目,需要开通正式环境。
API调试:支持swagger风格的调试功能,可以在浏览器直接进行数据的调试。
api接口地址是 https://
-dev(pd).apicloud-saas.com/api/modelName的形式。其中dev是测试环境,pd是正式环境。 在代码中可以通过接口Models.api.info()获取当前服务的域名及相应的环境(测试或者正式),返回信息为
//正式环境 { domain:'A***********-pd.apicloud-saas.com', env:'pd' } //测试环境 { domain:'A***********-dev.apicloud-saas.com', env:'dev' }
快速上手指南
在点击数据云的时候,选择 "开启数据云3.0" 即可开通相关功能。 开启后可在左侧菜单中选择 "数据模型" 进行数据表及数据的管理以及相关代码的编写。 对于新手,可以尝试引入我们的入门模板,通过点击预置模型的demo,即可把我们提供的示例模型引入到项目中。注意,为防止命名冲突,导入模型时不允许有任何同名的模型存在,否则导入失败。
如图所示:
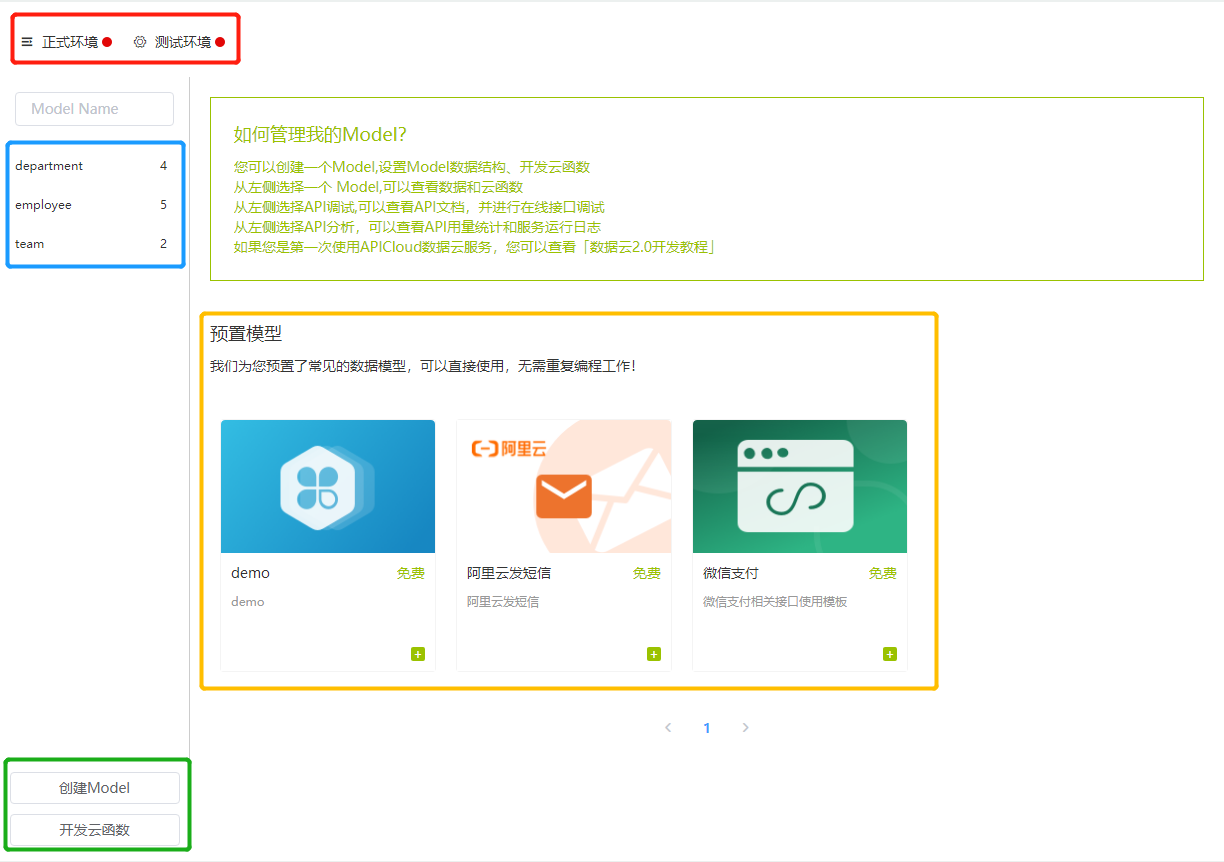
其中:
- 红色框内表示了当前后端服务的运行情况,绿色点表示服务处于开启状态,红色点表示服务处于关闭状态。
- 蓝色框表示当前服务的模型信息,通过点击相关模型可以查看该模型的具体数据情况。
- 绿色框中提供了两个按钮,分别可以创建新的数据模型以及编辑相关云函数。
- 黄色框表示我们为系统提供的预置模型,通过这些模型我们为开发者提供了一种代码复用的方式,减少了开发的工作量。
我们提供的示例是一个企业内部员工和部门的场景。大家可以也可以在模型操作区域中对导入的模型进行修改及数据操作。
如图所示:
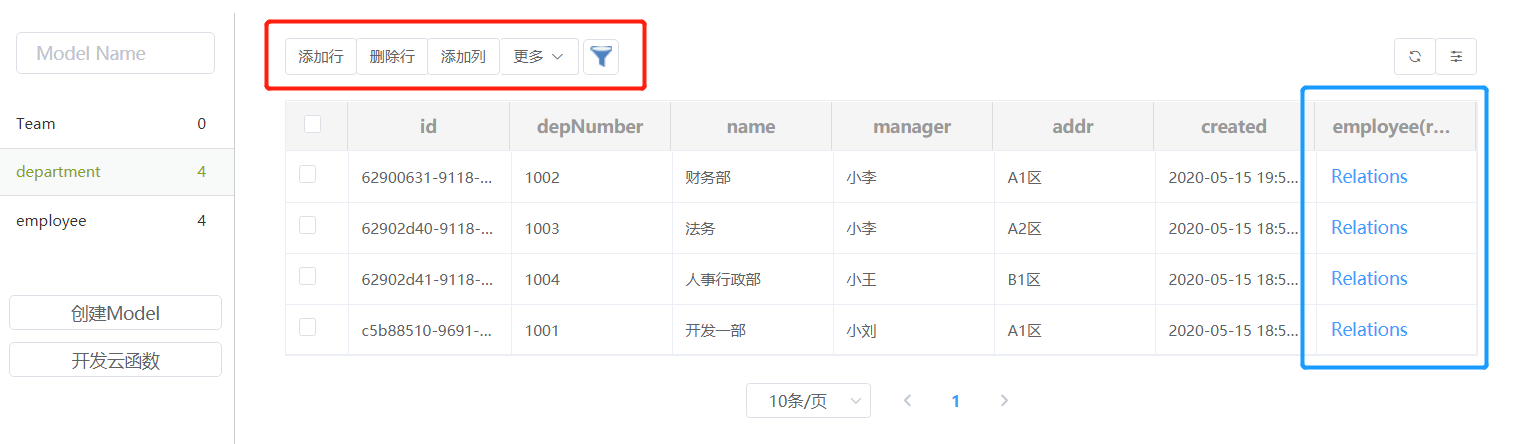
这里我们点击了department表,可以看到表的数据以及相关操作按钮。
- 红色框内标识了常用操作按钮,如添加数据,删除数据等;在更多的下拉列表中提供了其他一些针对模型的的常规操作,如删除行、删除数据、处理关联关系等。详见下边数据表操作相关介绍。
- 为方便用户进行关联关系查看,在表会默认增加了一列,点击会显示关联的相关内容,如上图的蓝色区域,通过点击该列将直接跳转到目标列并进行关联查询。
示例表的定义如下:
- 部门表:department
属性列表:
关联关系定义说明(鼠标放到关联关系名称的表头处可显示相关信息)"id": "string", //主键id "depNumber": "number", //部门编号 "name": "string", //部门名称 "manager": "string", //部门经理 "addr": "string", //部门地址 "created": "date", //创建日期"employee",//自定义的关联关系名称 "depNumber",//本表的关联字段 "hasMany",//关联类型 "employee",//被关联表名称,本例为employee表 "depNumber",//被关联表字段,这里是employee表的depNumber字段 - 员工表:employee
属性列表:
关联关系"id": "string", //主键id "name": "string", //用户姓名 "gender": "string", //性别 "birthday": "Date", //出生日期 "onboard_date": "Date", //入职时间 "title": "number", //职称:初级(1)、中级(2)、高级(3) "mobile": "string",//手机号 "photo": "string", //用户头像 "is_intern":"boolean", //是否是实习生 "hobby": "array", //爱好 "wage": "object", //工资以对象形式存在,字段包括basic(基本工资),bonus(奖金) "depNumber": "number", //部门编号 "created": "date", //录入日期"department",//自定义的关联关系名称 "depNumber",//本表的关联表字段,本例是employee表 "belongsTo",//关联类型 "department",//被关联表名称,本例为department表 "depNumber"//被关联表名称,department表的字段
如上表关联关系所示,一个部门创建后有部门编号地址等基本信息,员工表中有员工的基本信息同时通过depNumber可以关联到部门表。员工表中有两个属性比较特殊,其中爱好属性是一个数组,这样一个员工的爱好可以是一个列表形式;工资属性是一个对象,这么做的目的是工资由多部分组成,方便把不同部分通过一个属性进行表达。
目前我们支持的数据类型:String、Number、Boolean、Date、Array、Object
导入后在Databases中可见两个Model,department,employee 以及一些初始数据。 点击 "开发云函数" 按钮可以看到左侧模型列表以及Init,Global,Middleware三个系统提供的默认函数。
- Init函数:这是初始化函数,系统启动后会立即调用,可以用来做些初始化工作如定时任务等
- Global函数: 这是全局变量定义的地方,工具类函数和全局变量都可以在这里定义
- Middleware函数: 中间件函数,为用户体用一个所有接口统一处理的地方
点击任意Model将看到,默认内置的一些函数。每个Model下都有三种函数,
- 普通函数
- 钩子函数
- 远程函数
每种函数的介绍请见下方函数章节的详细说明。
这里我们看一下如果实现下边一些场景的实现方法。
新增员工
当员工入职时,我们要新增员工。我们先点击添加函数,在Model下拉框中选择employee模型,设置请求类型为post,同时添加相关的描述信息及参数,在函数定义中写入相关代码并保存,如果代码经过基本语法检测即可保存成功。这里提供了一个"创建员工信息"的函数,输入参数是一个object类型的对象,这个对象包含了需要新增员工过的相关信息,代码见如下:
employee.addEmployee = async (obj) => {
try {
await employee.create(obj);
return { statusCode: 200, message: "添加成功" }
} catch (err) {
throw new gError("添加失败!", "ADD_FAILED");
}
}
函数说明:
首先这是一个同步函数,对于同步操作需要使用await关键字。
create方法是一个公共的模型方法,employee是一个模型所以也自然拥有该方法,该方法将创建一个模型实例并把该实例存入数据库。详请请见模型方法一节的相关函数说明。
对于异常信息,这里提供了全局错误对象gError,该对象接收三个参数,第一个为错误信息;第二个为用户自定义错误码;第三个参数是接口返回的状态码,不填写默认返回400状态码。该异常信息也会记录到系统日志中,可以在日志中看到相关内容。
这样一个向用户表新增用户的接口就写好了,当然我们也可以使用系统默认提供的post方法为employee增加数据。函数保存成功后可以点击 "发布并重启测试环境" 完成发布工作。启动过程需要一些时间,可以通过日志按钮查看启动服务是否完成,打印 "Web server started" 即表示可以使用该测试环境。
此时点击接口联调将看到我们新增加的远程函数并可以在这里进行测试。
如图所示:
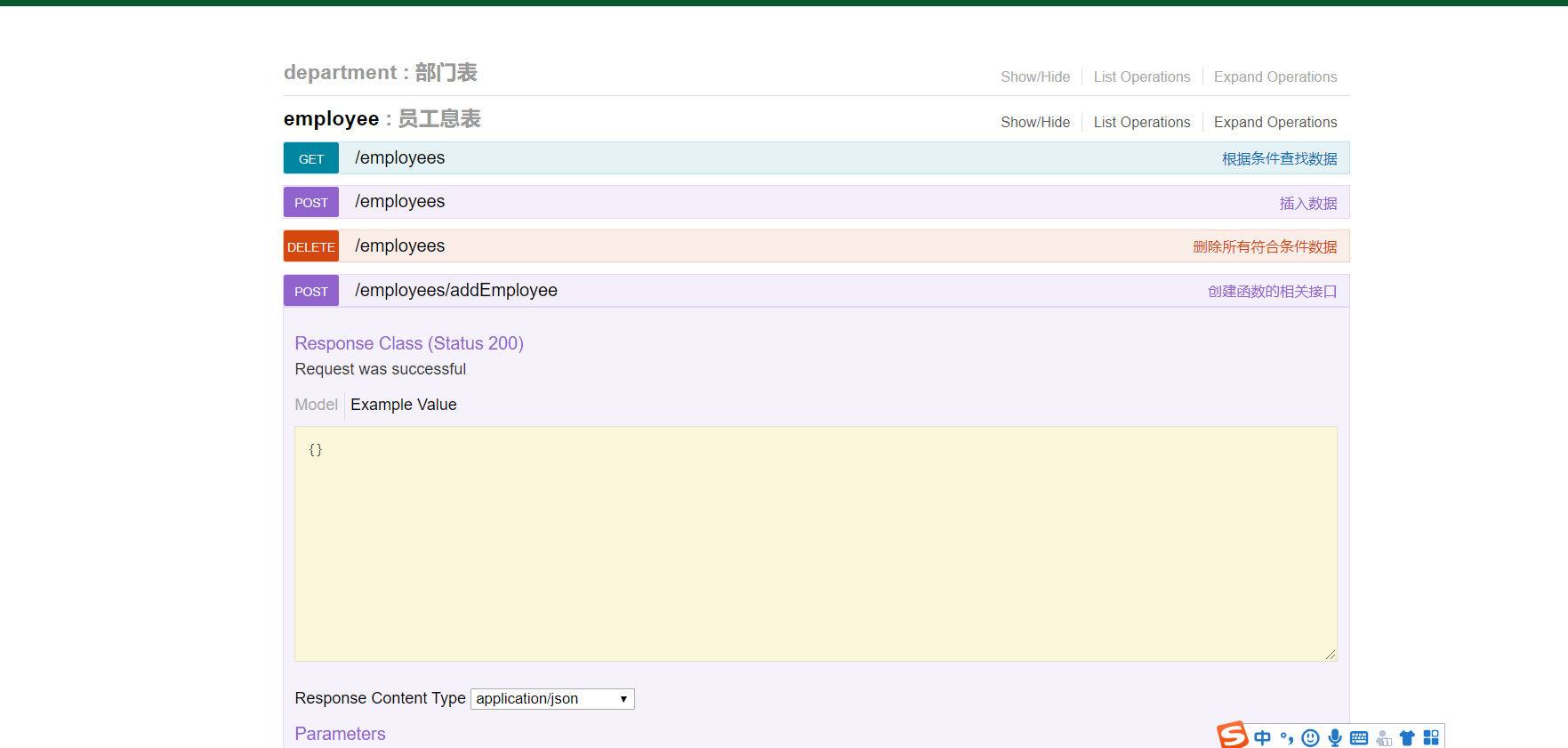
这里可以看到除了新增的接口外,模型下还提供了其他的一些接口,这是系统默认为每个Model生成的查询、插入数据、修改数据、删除数据以及查询数据总量的接口。这些接口不需要编写代码即可使用。当然也可以在模型的更多设置中关闭这些默认接口。
注:开发者也可以不使用官方提供的联调页面而使用浏览器或者postman等工具进行接口联调操作,接口的地址为
https://<appid>-dev.apicloud-saas.com/api
查看员工列表:
该接口提供给用户根据条件查找符合条件的员工,代码如下:
department.findEmployee = async(obj)=> {
try {
obj = obj || {};
let where=obj.where||{};
let limit=obj.limit||10;//分页每页显示条数
let skip=obj.skip||1;//分页页数
let order=obj.order||"title asc";//排序asc升序 desc降序
const list = await Models.employee.find({
where: where,//查询条件
order: order,//排序
limit: limit,//查询条数
skip: (skip - 1) * limit//页码换算成查询开始的位置
});
return { statusCode: 200,data:list, message: "成功" };
} catch (err) {
Models.api.console.error(err)
throw new gError( "查看失败!","FIND_FAILED");
}
}
函数说明:
这里用到了在本模型(department)中访问其他模型(employee)的方法,我们通过 "Models" 这个对象提供访问其他模型的方式,这个对象是模型内命名空间的一个对象,可以直接在远程函数、普通函数、构子函数中使用。
find方法与之前提到的create方法类似,也是一个公共模型方法,该方法将根据条件查找数据库中该模型下的数据。该方法支持"where","limit"等关键字,详见模型方法一节相关说明。
在异常处理中的Model.api.console方法,这是系统默认模型api下提供的打印日志方法,该方法打印的信息将存储在系统日志中。该方法有四种日志等级:debug, info, warn, error 。可以在启动日志中看到不同标签下的日志信息,开发者可以根据需要在代码中使用。
关联关系
数据之间的关联关系是业务中常用的场景,我们提供了belogsTo,hasMany两种关联关系,这里我们以demo中的示例描述下新版数据云如何处理关联关系。一个部门中包含多个用户,一个用户只能属于一个部门,这样在定义表关联关系的时候,需要分在两个表中分别定义belongsTo和hasMany关系。 数据表关系定义后就可以在代码中通过关键字Include来把关联关系的数据引入,具体见department模型下的"查看部门列表"函数。
department.findlist = async (obj) => {
try {
obj = obj || {};
let where = obj.where || {};
let limit = obj.limit || 10;//分页每页显示条数
let skip = obj.skip || 1;//分页页数
let order = obj.order || "depNumber asc";//排序asc升序 desc降序
let fields = ['id', 'name', 'depNumber', 'manager', 'addr'];//显示字段
const list = await department.find({
fields: fields,//显示字段
where: where,//查询条件
order: order,//排序
limit: limit,//查询条数
skip: (skip - 1) * limit,//页码换算成查询开始的位置
include: [//关联包含查询
{
relation: 'employee', //关联表
scope: {//范围关联限制
where: { gender: '男' },
fields: ['name', 'title']
}
},
//...可以关联多个表,写法同employee
]
});
return { statusCode: 200, data: list, message: "成功" };
} catch (err) {
//console.log(err);
throw new gError("查看失败!", "FIND_FAILED");
}
}
//只需关联一个表
department.findlist = async (obj) => {
try {
// ... your codes
const list = await department.find({
// ... your codes
// 关联单个关系
include:{
relation: 'employee', //关联表
scope: {//范围关联限制
where: { gender: '男' },
fields: ['name', 'title']
}
}
//... your codes
});
return { statusCode: 200, data: list, message: "成功" };
} catch (err) {
throw new gError("查看失败!", "FIND_FAILED");
}
}
//如果内层不需要字段过滤
const list = await department.find({
// ... your codes
// 关联单个关系
include:["employee","department"]
// ... your codes
});
函数说明
- 该函数中使用了include关键字,该关键字会把模型定义的关联关系表引入到结果集中,这里我们把
employee这个关联名称带入,该名称是在创建关联关系的时候我们设置的。 - 关联会默认返回关联字段值
- 外层进行fields过滤的时候,需要将当前表关联字段加入,比如上面例子中,
fields包含关联字段depNumber,才会返回关联关系employee - 返回
belongsTo返回关联关系数据对象
employee:{
// ... data
}
hasMany返回关联关系数据数组
employee:[{
// ... data
}]
全局设置
云设置提供了一些全局设置的入口,这些全局设置在正式环境和测试环境中同时生效。
接口验证设置:
接口安全在后端开发中是一个重要方面,我们提供了接口验证设置,开启这个设置后后端服务会从所有模型的接口头中自动读取SecretKey中设置的字符串,只有在请求头"x-apicloud-mcm-key"中设置secretKey的并且匹配成功的请求可以获取到数据,对于没有权限的接口,将返回400,并提示'默认接口无操作权限'。注意,重置该key只有重启后端服务后会生效。如果变更了SecretKey并重启服务,之前的接口请求将变为无权限操作被拦截。
token认证:
开启后,在每次请求时,云服务中间件会自动获取在header中以这里token头命名的请求头的值,并把它赋值给accessToken,开发者可以在程序中直接通过req.accessToken使用,无需再次解析header。如果开发者没有在 "设置token头" 的位置设置token名称,默认将取 "access-token" 作为请求头名称。
session认证:
APICloud提供的云服务支持通过session机制进行权限校验。当开发者希望在服务器使用session时,只需在全局配置中开启session按钮,并设置session的有效期,云服务会自动开启用户session信息的存储功能。用户在云函数中可以直接在请求处理函数中,通过"req.session"对希望在session中存储的数据进行读取或者设置。这里设置的ttl是请求的有效期,单位是秒,更多信息设置请参考 ["express-session"] (https://www.expressjs.com.cn/en/resources/middleware/session.html)的相关设置说明。
服务设置:
可以通过这里的查看正式环境和测试环境的状态,并进行相关的开启和关闭操作。
文件存储:
如果涉及到服务器端的数据存储,请开启文件存储,我们提供的第三方接口方便用户把数据直接上传到文件云存储中。该服务开启后会一直开启,不会关闭。
域名绑定:
在使用正式环境的时候,我们建议用户上传自己的域名信息到服务器,这样云服务提供的相关接口可以使用自己的域名进行访问。
支持自己域名的绑定和解绑,在云设置中操作。
如图:
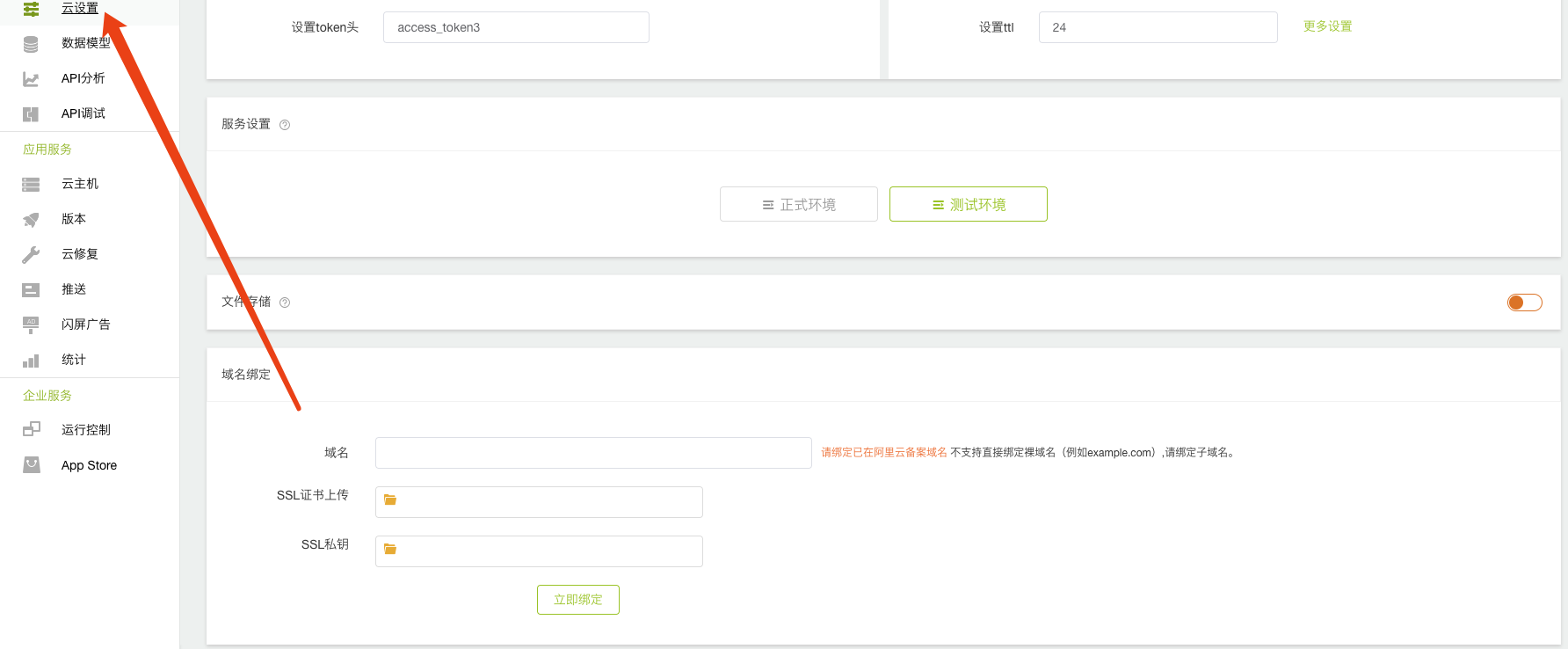
绑定的域名必须在阿里云完成备案方可被成功解析。如果使用APICloud提供的域名,则需要完成实名身份认证方可使用。
云数据库
数据表定义
- 创建数据表 [创建Model]
- Model名称支持下划线(_)连接的英文单词
- 数据表描述
- 删除数据表
- 更多->删除Model
- 会将表数据删除,请谨慎删除
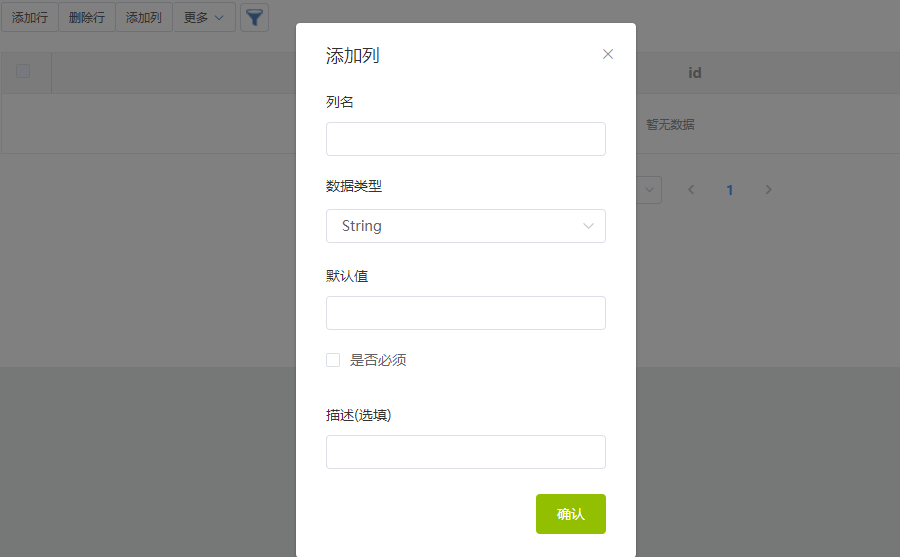
- 增加字段
- 列名
- 数据类型支持
string,date,number,boolean,array,object - 默认值/默认函数
- 是否必须:如果是必须,这个字段必填,否则会保存失败
- 描述:该字段的描述
- 根据模型提供的接口,模型字段使用复数形式,比如定义 'team' 转为 'teams'
删除字段
- 更多 -> 删除列 -> 选择需要删除的列 -> 确定
- 删除列会同时将这列的数据删除,请谨慎删除
- 如果这个字段上有关联关系,也会被删除
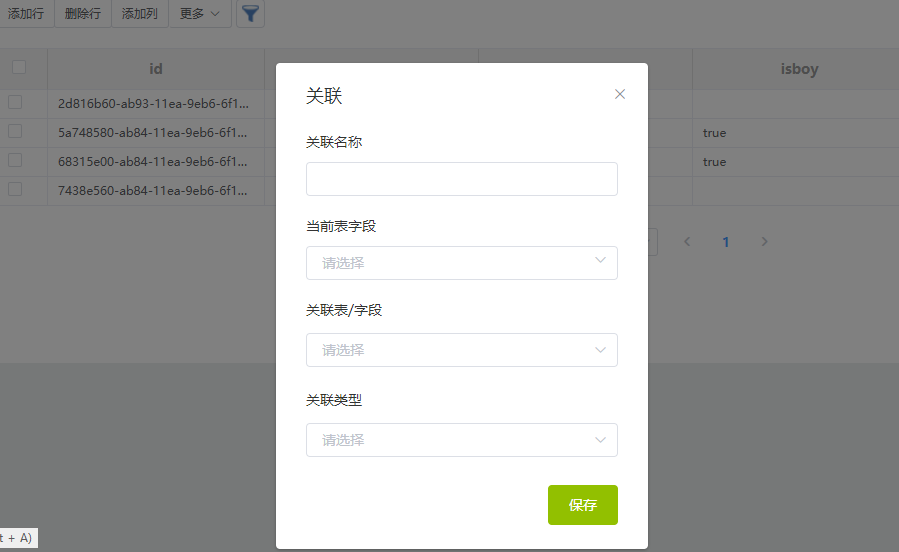
关联
- 更多 -> 关联
- 关联名称(自定义)
- 当前表字段(从当前表已有字段中筛选)
- 关联表/字段(选择需要关联表的字段)
- 关联类型(
belongsTo,hasMany) - 添加关联后,可以通过关联名称跳转到关联表
 提供了新增,编辑,删除,获取的方法,模型修改后,重启才能生效
提供了新增,编辑,删除,获取的方法,模型修改后,重启才能生效
数据导入
- 更多 -> 导入数据 支持csv和json格式(需是从mongo数据库中用命令mongoexport导出的格式)
数据导出(JSON)
- 更多 -> 导出数据
设置索引
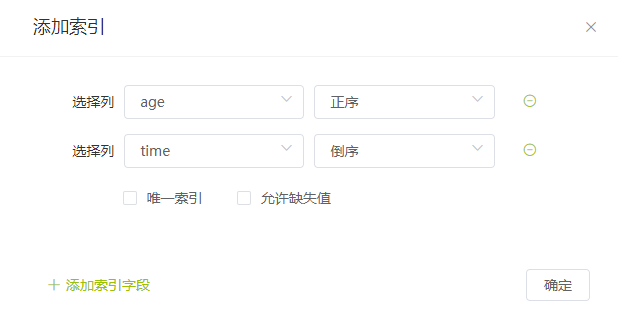
添加【更多】 -> 【索引】 -> 【添加索引】
- id字段的索引为系统内置索引,不可更改
- 索引根据零个以上的[字段名称+排序]组合作为候选码,重复创建会失败
- 创建唯一索引必须保证相关字段的数据无重复,缺失值相当于一个特殊值
- 允许缺失值,即允许字段为空
删除 【更多】 -> 【索引】 -> 【删除】
- id字段的索引不可以删除
示例
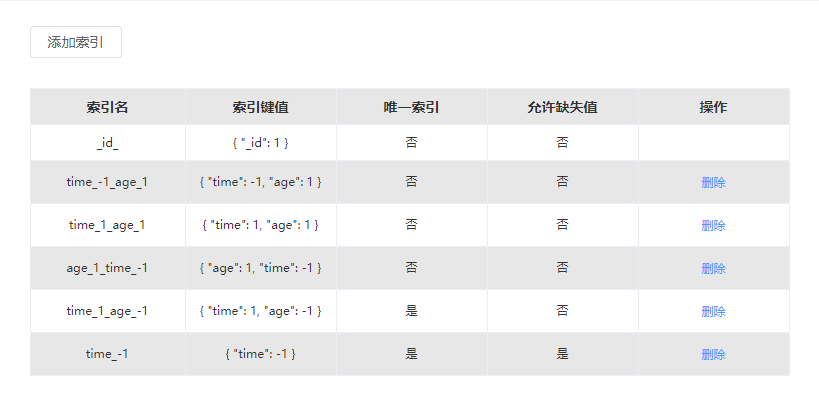
表的基本操作
- 增加数据(id不可修改)
- 如果该字段设置了默认值,后台会自动填充
- 不符合字段类型的值且不能转换成当前类型将不能保存成功
- 删除数据
- 选中需要删除的行,点击【删除行】
- 修改数据
- 双击需要修改的行,可以进行编辑,然后【保存】/【取消】
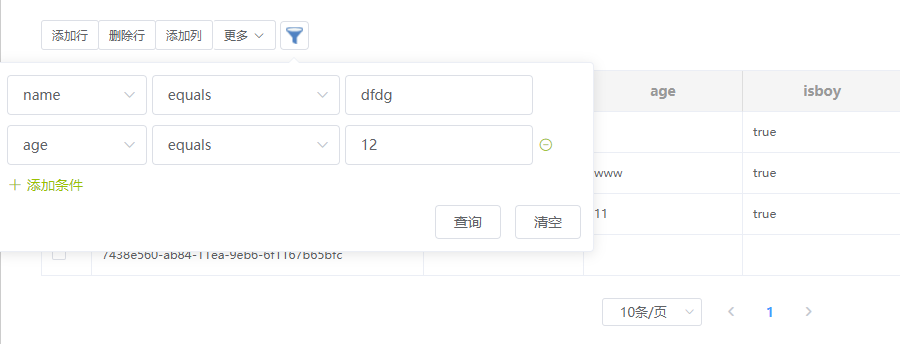
- 筛选数据
- 多行为
and关系
- 多行为
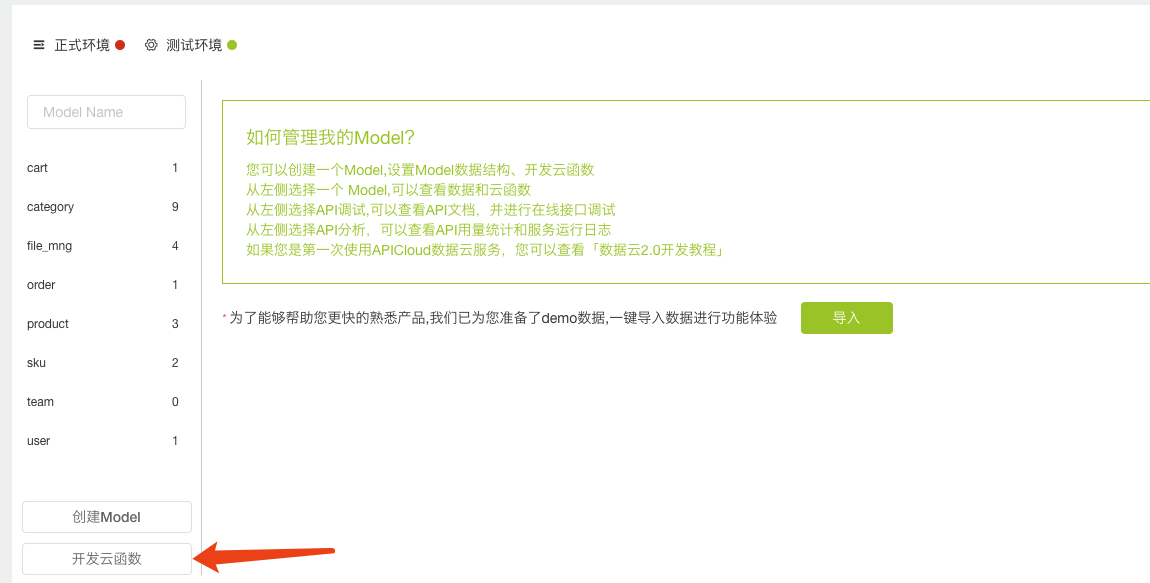
云函数
函数是APICloud为开发者们提供的一种执行环境,帮助开发者在无需购买服务器的情况下运行代码。如图点击开发云函数:
初始化(Init)函数
系统启动时,初始化函数会被调用一次,可以在此函数中进行一些初始化的工作,如定时任务,变量初始化等操作,云函数使用到的第三方包也需要在初始化函数中进行声明。
如图

全局对象
定义的全局对象,在整个工程中都可以调用。
使用说明
在其他函数中使用时,用G.常量(或方法)
如图:s
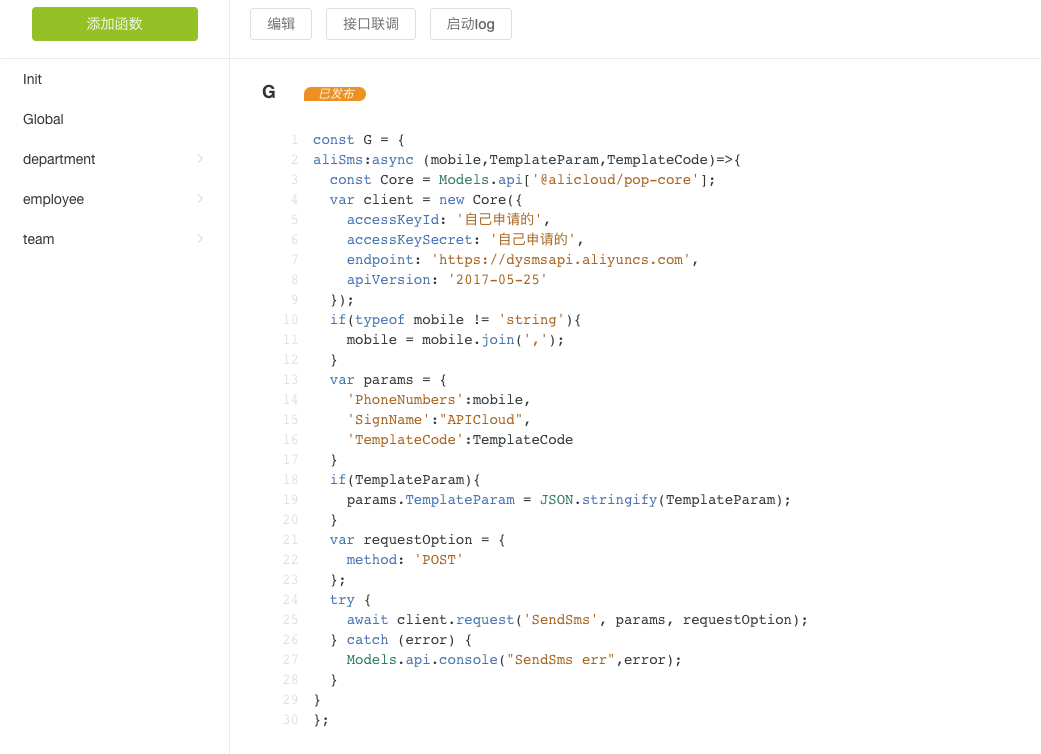
中间件函数(MiddleWare)
使用说明
中间件函数能够访问请求对象 (req)、响应对象 (res) 以及应用程序的请求/响应循环中的下一个中间件函数。下一个中间件函数通常由名为 next 的变量来表示。
中间件函数可以执行以下任务:
- 执行任何代码,通常是统一的接口验证、或者接口处理
- 对请求和响应对象进行更改
- 结束请求/响应循环
- 调用堆栈中的下一个中间件函数
注意
如果当前中间件函数没有结束请求/响应循环,那么它必须调用 next(),以将控制权传递给下一个中间件函数。否则,请求将保持挂起状态。
如图:
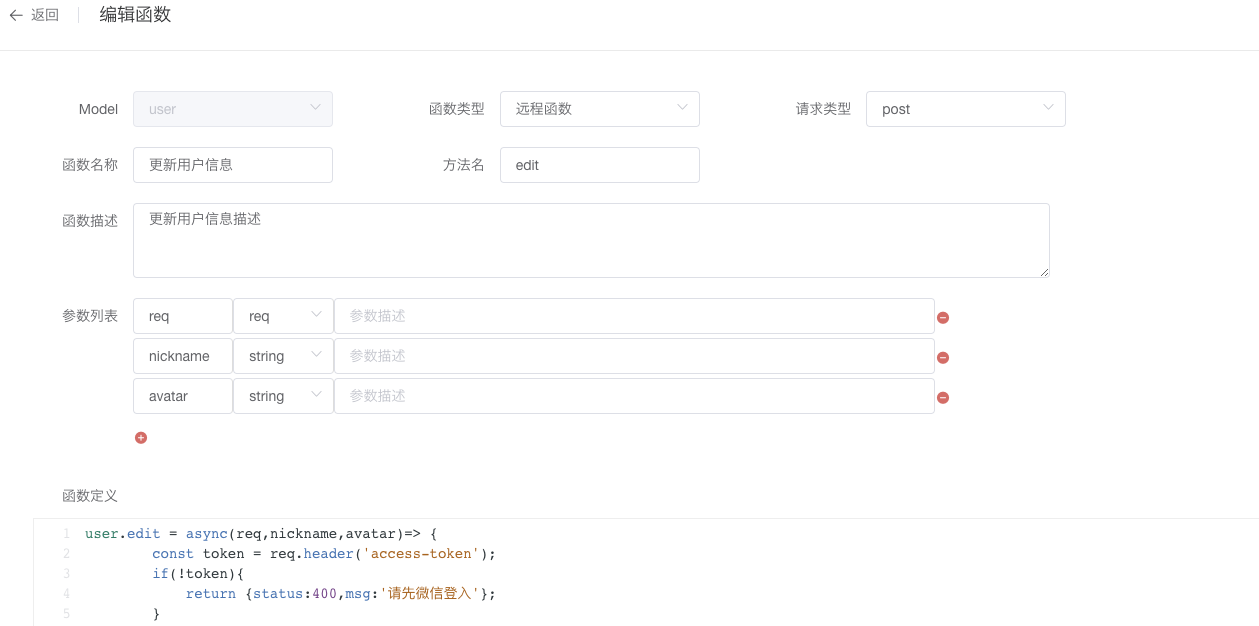
远程方法
带路由的方法,允许接口访问。
使用说明
Model:选择一个模型,这个方法属于这个模型。
函数名称:是标记这个函数的,可以使用中文。
函数类型:选择远程函数。
方法名:要定义的方法名,在一个类中不能重复,要符合JS中方法名的定义规则。
方法类型:我们提供了6种接口请求方式,分别是get,post,patch,put,del,all。
参数列表:可以添加这个函数需要的参数。我们也提供6种参数类型,分别是string,number,boolean,object,array,req,res。其中req类型是为了在方法中获取request而设定,res类型是为了在方法中获取response而设置。
函数定义:定义函数的实现的内容。例如模板employee model中创建员工信息的函数addEmployee:
try {
await employee.create(obj);
return { statusCode: 200, message: "添加成功" }
} catch (err) {
throw new gError( "添加失败!","ADD_FAILED");
}
如图:
钩子函数
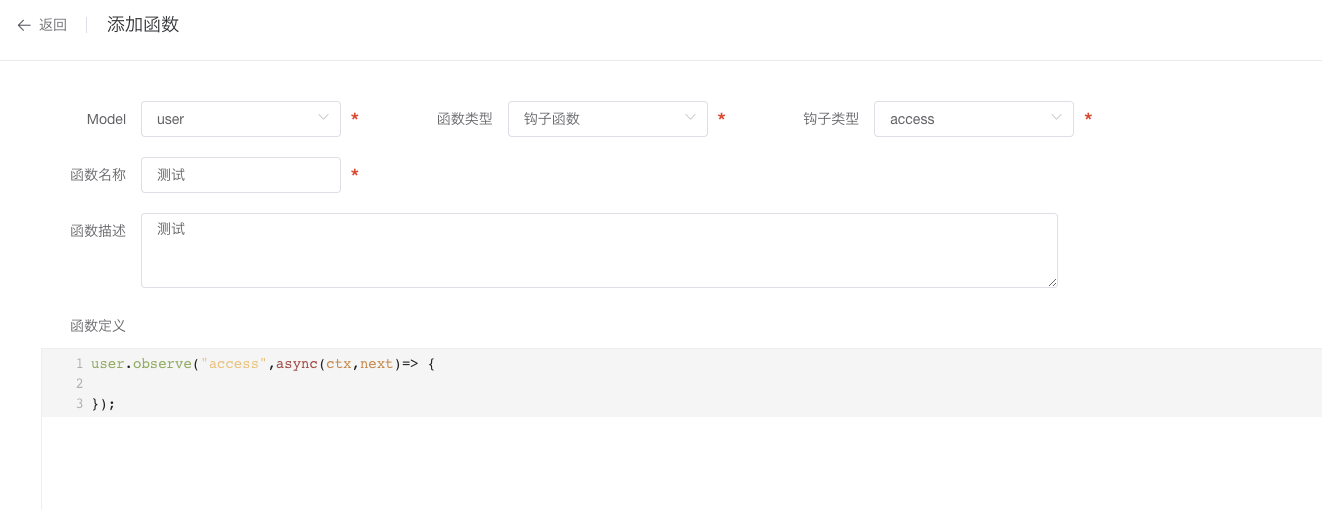
在外部调用access,save的前后,delete前后时,触发的函数。
使用说明
Model:选择一个模型,这个方法属于这个模型。
函数名称:是标记这个函数的,可以使用中文。
函数类型:选择钩子函数。
方法名:要定义的方法名,在一个类中不能重复,要符合js中方法名的规则。
钩子类型:提供5种类型,分别是access, before save, after save, before delete, after delete。
函数定义:定义函数的实现的内容。
如图:
普通函数
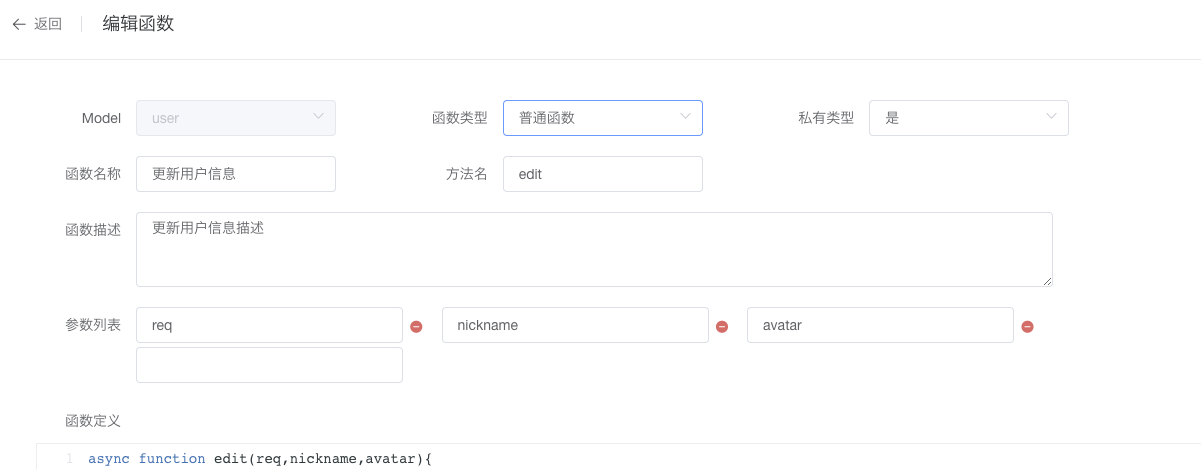
定义在本模块中或者其他模块中使用的函数。
使用说明
Model:选择一个model,这个方法属于这个模型。
函数名称:是标记这个函数的,可以使用中文。
函数类型:选择普通函数。
方法名:要定义的方法名,在一个类中不能重复,要符合JS中方法名的规则。
私有类型:选择是或者否。如果是时,它只能在本模块中使用;反之,其他模块可以使用该函数。
参数列表:可以添加这个函数需要的参数。
函数定义:定义函数的实现的内容。
如图:
非私有类型普通函数使用说明
主要用在工具类型模型内中创建,供其他模型调用。在本model和其他model内使用时,都是加上model的名称,例如:在user这个model中有个getToken的非私有普通函数。
在本model内使用如下:
user.getToken()
其他model内使用如下:
Models.user.getToken()
私有类型普通函数使用说明
只能在本模型中使用,使用时,直接调用函数的名称。
开发(测试)环境和正式环境
发布到测试环境
当一个函数方法创建、编辑后,就会处于草稿状态。发布后的状态有新增、编辑、删除等。
函数状态列表:
- 草稿:当一个函数方法被创建、编辑保存后的状态。
- 新增:当一个函数方法在草稿状态发布后,此函数方法没在正式环境中时,就是新增状态。
- 编辑:当一个函数方法在草稿状态发布后,此函数方法在正式环境有中时,就是编辑状态。
- 删除:当一个函数方法在删除后发布,此函数方法在正式环境有中时,就是删除状态。
- 删除待发布:当函数已发布到测试环境后再进行删除操作的函数,会显示为此状态 。
同步到正式环境
当函数上方出现同步按钮后,就说明该函数可以同步到正式环境,同步后,函数方法就处在已发布的状态。
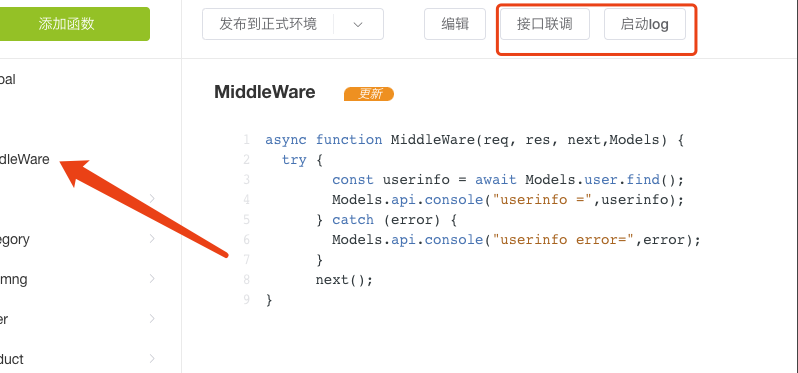
接口联调及启动log
接口联调按钮是启动 swagger页面 查看接口。 启动log 按钮 是显示程序启动中的log信息,包括用户主动输入的。
如图:
API调试
在函数编辑的地方有联调按钮,点击联调后将打开接口联调的界面,接口联调通过swagger实现。只有测试环境提供联调功能。正式环境出于安全考虑不开放联调功能。 接口联调的地址:
- 测试环境: https://
-dev.apicloud-saas.com/api/
如:appid 是 A604565411509 的应用,则它的接口联调地址为
如图所示:
 这里打开了测试环境的联调地址。
其中coffeeShop是类名称,在下边可以看到默认提供的五个接口,这些接口分别是查找数据、插入数据、删除符合条件的数据、按条件查询表中的数据总数以及更新数据。默认接口不需要写代码即可自动生成。
这里打开了测试环境的联调地址。
其中coffeeShop是类名称,在下边可以看到默认提供的五个接口,这些接口分别是查找数据、插入数据、删除符合条件的数据、按条件查询表中的数据总数以及更新数据。默认接口不需要写代码即可自动生成。
自定义的远程方法也会在这里展示出来。如图中的userRate则是在coffeShop下定义的远程方法。
点击接口名称将打开接口的调试详情。如图:
 在这里可以模拟接口请求。
参数字段跟用户定义的接口参数一致,其中的描述字段内容即为在函数页面编写的描述内容。可以描述该字段的意义以及传值的示例,方便联调时使用。
在这里可以模拟接口请求。
参数字段跟用户定义的接口参数一致,其中的描述字段内容即为在函数页面编写的描述内容。可以描述该字段的意义以及传值的示例,方便联调时使用。
也可以使用浏览器或者postman等工具进行接口联调测试。
注意:生成的接口的模型名称后加“s”,如 coffeShop 生成的模型为 “http://
模型API接口及条件过滤
我们为开发者提供了一些内置的模型函数,方便开发者操作数据库,完成对数据表的增删改查操作。
同时这里也会对条件过滤做相关介绍。 模型提供的函数列表:create,upsert,updateAll,find,findById,findOne,count,exists,destroyAll,destroyById
同时Models也提供了访问其他模型的方法,可以通过 "Models.模型名称"的方式在函数中对其他模型的方法进行调用。
模型API
插入数据
create(data)
- 生成一个模型实例并把数据存入数据库
- 代码示例:
try { let obj = { "name": "行政部", "manager": "Dave", "addr": "bj", "created": "2020-05-21", "depNumber": 1001 } await department.create(obj); return { statusCode: 200, message: "添加成功" } } catch (err) { throw new gError("添加失败!", 100); }
upsert(data)
- 根据ID检查模型实例在数据库中是否存在,如果存在则做更新操作,把manager字段更新为Dave;如果不存在则插入这条数据。
- 代码示例:
try { let obj = { "id": "62900631-9118-11ea-8a27-7bc5ca674e51", "manager": "Dave", } await department.upsert(obj); return { statusCode: 200, message: "添加成功" } } catch (err) { throw new gError("添加失败!", 100); } - 说明:查找数据库中id为62900631-9118-11ea-8a27-7bc5ca674e51的数据,如果存在则更新manager为Dave,否则插入这条数据。
更新数据
- updateAll([where], data)
- 根据筛选条件更新数据表所有数据
- 代码示例:
await department.updateAll( {manager:'Dave'}, {manager:'Bill'}); - 说明:把部门表中的经理名称为Dave的替换为Bill
删除数据
destroyAll([where])
- 根据筛选条件进行删除所有符合条件数据
- 代码示例:
await department.destroyAll({manager:'Dave'}); - 说明:删除所有名称为Dave的数据,注意[where]不需要写过滤器名称,直接写里边的对象,需要与[filter]的用法区分。
destroyById(id)
- 根据模型的ID进行删除
- 代码示例:
await department.destroyById({id:'62900631-9118-11ea-8a27-7bc5ca674e51'});
查询数据
find([filter])
- 根据模型的ID进行删除
- 代码示例:
const list = await Models.employee.find({ where: {"depNumber":1001},//查询条件 order: "title desc",//排序 limit: 5,//查询条数 skip: 1//页码换算成查询开始的位置 }); - 说明:查找部门编号是1001的所有数据,根据职级降序排列,从第二条开始,只查找5条数据,注意find([filter])中的filter特定指代条件过滤器,所以即使只接一种也要把条件过滤器的名称带出来,不能只写条件过滤器后的对象,如 await Models.employee.find({where: {"depNumber":1001}}) 不可以写成 await Models.employee.find({"depNumber":1001}),此处注意与updateAll函数中的where进行区分。
findById(id, [filter])
- 根据模型的ID进行查找,filter可以定义需要显示的字段内容
- 代码示例:
const list = await Models.employee.findById("62900631-9118-11ea-8a27-7bc5abcccccc"); - 说明:查找主键id为 "62900631-9118-11ea-8a27-7bc5abcccccc" 的员工信息
findOne([filter])
- 同find类似,只是返回一条记录
count([where])
- 根据where条件查找符合条件的数据条目数
- 代码示例:
const num = await Models.employee.count({"depNumber":1001}); - 说明:查找符合部门id是 1001 的员工总数,注意,此处的[where]不需要写过滤器名称,直接写里边的对象。
exists(id)
- 根据模型id判断这个模型的实例是否存在
地理位置支持
- 设置
- 设置字段类型为数组,只有经度和纬度两个元素
[lat,lon] - 为该字段添加
2d索引 - 2d 索引,为2dsphere,array字段用作地理位置使用的时候,必须先建此索引
- 设置字段类型为数组,只有经度和纬度两个元素
- 查询
- 关键字
- near 后跟中心坐标点
- maxDistance 最大半径
- minDistance 最小半径
- unit 半径单位
- meters 默认单位
- kilometers
- miles
- feet
- 关键字
- 注意
- 目前只支持
find```js //设在department表有location字段,索引为2d let data = await department.find( { where: { location: {
} } } )near: [12, 12], maxDistance: 2000, unit: "kilometers"
- 目前只支持
说明:查找以[12,12]半径 2000 km内的点
### 聚合查询数据 *aggregate*
针对mongodb的聚合查询,我们放开了aggregate方法,用户可以根据需要直接调用相关函数。aggregate的具体用法请参考mongodb的相关文档。https://docs.mongodb.com/manual/reference/command/aggregate/#dbcmd.aggregate
### 条件过滤器
条件过滤器(filter)主要用于条件筛选,比如查询操作,这将读取数据并返回一组数据集,我们可以通过RESTFUL接口的格式来查询模型自动生成的数据接口,也可以通过Node格式通过代码方式查询数据。:
条件过滤器主要有以下几种类型:
<div style='display: none'>
- fields
- limit
- order
- skip
- where
- include
</div>
|名称 | 类型 | 描述 |
|-------- |--------| -----|
|fields | Object |决定是否显示某些字段|
|limit | Number|限定返回数据的条目数|
|order | String|设置按照哪个字段排序,是正序还是逆序|
|skip | Number|跳过指定数量的数据|
|where | Object|设置查询的条件|
|include | String,Object,Array|根据关联查询|
### 请求语法
- **Node 函数语法**
<small>条件过滤器需要是一个Json格式的对象,filterType特指六种条件过滤器类型</small>
```js
{ filterType: spec, filterType: spec, ... }
//在查询中可以增加多个过滤器
example
let whereFilter = {
where: { "id": 1201 },
fields: { "manager": true, "addr": true },
limit: 5
};
await employ.find(whereFilter)
Stringified 语法
Node 的语法也可以进行stringified,然后通过restful接口的方式进行查询
{ filterType: spec, filterType: spec, ... }example
GET /mcm/api/users?filter={"where":{"id":1234},"fields":{"manager":true,"addr":true},"limit":5}
fields过滤器
设置字段是否显示在结果列表内。 如下示例只显示员工表的姓名、性别和出生日期等字段
Node 语法
{ fields: { "propertyName": <true|false>, "propertyName": <true|false>, ... } }Examples
let fieldsFilter = { fields: {"name": true, "gender": true, "birthday": true} } await Models.employee.find(fieldsFilter)- Stringified 语法
Examplesfilter={ "fields": {"propertyName": <true|false>, "propertyName": <true|false>, ... } }GET /api/employees?filter={ "fields": {"name": true, "gender": true, "birthday": true} }
limit过滤器
限制返回的记录数 返回员工表的5条结果
Node 语法
{limit: n}Examples
await employee.find({"limit": n});Stringified 语法
filter={"limit": n}Examples
GET /api/employees?filter={"limit": 5}
order过滤器
查询结果按照指定字段排序,asc升序,desc降序
Node 语法
按某个属性排序示例:
{ order: "propertyName <ASC|DESC>" }按一组属性排序示例:
{ order: ["propertyName <ASC|DESC>", "propertyName <ASC|DESC>",...] }Examples
let orderFilter = { order: "title asc" } await Models.employee.find(orderFilter)Stringified 语法
按某个属性排序示例:
filter={ "order": "propertyName <ASC|DESC>" }按一组属性排序示例:
filter={ "order": ["propertyName <ASC|DESC>", "propertyName <ASC|DESC>",...] }Examples
按title进行倒叙排序,并限制返回3条数据
GET /api/employees?filter={"order": "title DESC", "limit": 3 }
skip过滤器
跳过指定记录数进行查询
Node 语法
{ skip: n }Examples
await employee.find({"skip": 5});Stringified 语法
filter={"skip": n}Examples
GET /mcm/api/employee?filter={"skip": 5}
条件过滤(Where filter)
在过滤器指定一组逻辑条件匹配,类似于一个where子句的SQL查询
- Nodejs 语法
Examples{where: {"property": value}} {where: {"property": {"op": value}}}await employee.find({where:{"name":"zds"}}) - Stringified 语法
Examplesfilter={"where": {"property": value}} filter={"where": {"property": {"op": value}}}GET /mcm/api/employees?filter={"where":{"name":"zds"}}操作符(op)
| 操作符 | 说明 |
|---|---|
| and | 逻辑与 |
| or | 逻辑或 |
| gt,gte | 大于(>),大于或等于(> =)。只有效数值和日期值 |
| lt,lte | 小于(<),小于或等于(< =)。只有效数值和日期值 |
| between | 在…之间 |
| inq,nin | 在/不在一个数组之内 |
| ne | 不等于(!=) |
| like,nlike | like/not like 操作符返回符合正则表达式的数据 |
eq 查找完全匹配的记录
Nodejs 语法
{where: {"property": value}} {where: {"property": {"eq": value}}}Examples
await employee.find({where:{"name":"zds"}})Stringified 语法
GET /mcm/api/employee?filter={"where":{"name":"zds"}}
gt and lt 查找大于或者小于的记录
- Stringified 语法
GET /mcm/api/employees?filter={"where":{"title":{"gt":1}}} GET /mcm/api/employees?filter={"where":{"title":{"lt":5}}}
- Stringified 语法
and / or
条件与和条件或
- Nodejs 语法
{where:{<and|or>[{"property": value},{"property": value}]}- Stringified 语法
查找职级为1并且部门编号为1001的记录GET /mcm/api/employees?filter={"where": {"and": [{"title": "1"}, {"depNumber": "1001"}]}}
- Stringified 语法
- Nodejs 语法
between
- Nodejs 语法
{where:{"property": {"between":[val1,val2]}}} - Stringified 语法
GET /mcm/api/employees?filter={"where":{"title":{"between":[0,3]}}}
- Nodejs 语法
like and nlike
- Nodejs 语法
{where:{"property": {like/nlike:value}}} - Stringified 语法
GET /mcm/api/Posts?filter={"where":{"title": {"like": "M.+st"}}} GET /mcm/api/Posts?filter={"where":{"title": {"nlike": "M.+XY"}}} GET /mcm/api/Users?filter={"where": {"name": {"like": "%St%"}}} GET /mcm/api/Users?filter={"where": {"name": {"nlike": "M%XY"}}}
- Nodejs 语法
inq
- Nodejs 语法
{where:{"property": {inq: [val1,val, ...]}}} - Stringified 语法
GET /mcm/api/medias?filter={"where": {"keywords": {"inq": ["foo", "bar"]}}}
- Nodejs 语法
include过滤器
查询定义过hasMany,belongTo关系的相关表的数据
- Nodejs 语法
await employee.find({"include": "employeedepNumber"}) - Stringified 语法
GET /mcm/api/employees?filter={"include": "relatedModel"} GET /mcm/api/employees?filter={"include": ["relatedModel1", "relatedModel2", ...]} GET /mcm/api/employees?filter={"include": {"relatedModel1": [{"relatedModel2": "propertyName"} , "relatedModel"]}} - Examples
GET /mcm/api/employee?filter={"include":"employeedepNumber"}
事务支持
- 事务的默认隔离为可重复读
- 每个事务只能回滚/提交一次
- 对数据操作中使用 { transaction: tx } 即可加入此次事务
- 事务使用举例
//添加部门及成员
department.addDepEmp = async()=> {
let tx = await department.beginTransaction({});//开始事务
try {
let dp = await department.create({
addr:"A2小区",
depNumber:1005,
manager:"小闫",
name:"财务部"
}, { transaction: tx });
await Models.employee.create({
name:"微微",
gender:"女",
birthday:"1995-05-02",
onboard_date:"2017-11-11",
title:3,
mobile:13200000000,
is_intern:false,
depNumber:1005,
language:["中文","英文"]
}, { transaction: tx });
throw new gError('在这里出错了', "CREATE_FAILED")
await tx.commit();//提交事务
return { statusCode: 200, message: "成功" };
} catch (err) {
await tx.rollback();//如果失败,回滚事务
throw new gError("查看失败!", "FIND_FAILED");
}
};
说明
- 在一个事务中,添加部门及部门下的人员,两者同时成功或其中有一失败,全部回滚。
- 上面的事务,我们在
employee表添加了一条记录后,手动添加错误throw new gError('在这里出错了', "CREATE_FAILED"),会触发tx.rollback(),数据表中最终不会添加数据 - 去掉上面的
throw new gError('在这里出错了', "CREATE_FAILED"),事务提交,在数据库的 department 和 employee 下会分别增加一条记录 - 将某个数据库操作加入事务,需要按规范添加
{transaction:tx},tx为定义的事务
事务操作列表
//增加记录
let tx = await department.beginTransaction({});
let dt = await department.create(addr: "A2小区", depNumber: 1005, manager: "小闫", name: "财务部", { transaction: tx });
//更新记录
await department.updateAll({ depNumber: 1005}, { name: "大客户项目部" }, { transaction: tx });
//查找所有符合条件的记录
await department.find({ where: { depNumber: 1005} }, { transaction: tx });
//查找一条符合记录的记录
await department.findOne({ where: { depNumber: 1005 } }, { transaction: tx });
//删除所有符合要求的记录
await department.destroyAll({ depNumber: 1005 }, { transaction: tx });
//根据id删除符合条件的记录
await department.destroyById(dt.id, { transaction: tx });
//统计所有
await department.count({ transaction: tx });
内置模块
包含上传七牛云,微信支付的相关接口
上传到七牛云接口
利用七牛提供的sdk封装的方式,减少用户开发量。使用时要在远程函数中调用,返回文件的大小,名称和地址,最大支持500M的上传。其中的req 参数是 HTTP request object。
如图所示:
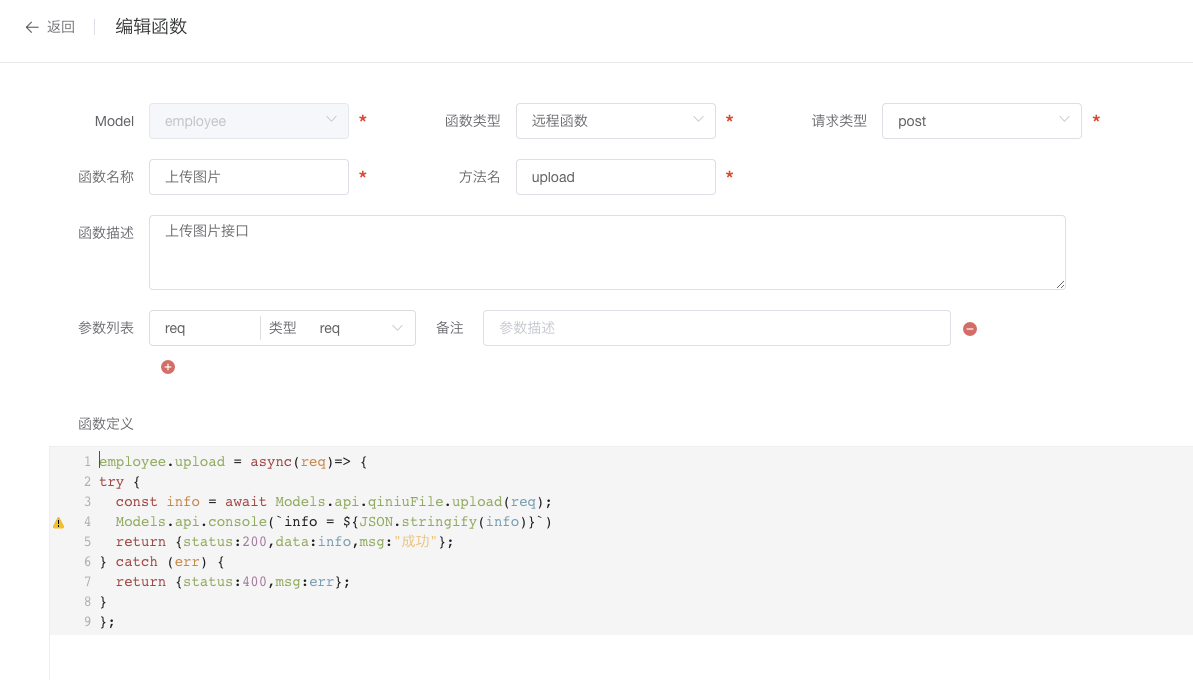 使用示例
使用示例
{
try {
const info = await Models.api.qiniuFile.upload(req);
return { status: 200, data: info, msg: "成功" };
} catch (err) {
return { status: 400, msg: err };
}
}
返回示例
{
"size": "12341",
"name": "图片名.png",
"url": "http://*****.png"
}
七牛云删除接口
{
try {
await Models.api.qiniuFile.delete('图片名.png');
return {status:200,msg:"成功"};
} catch (err) {
return {status:400,msg:err};
}
}
微信支付接口
封装了微信的统一下单接口,方便用户使用。示例
{
const info = await Models.api.wxpay.pay(appid,mch_id,product_id,key,trade_no, trade_type, body,detail, openid, total_fee, time_expire, notify_url)
}
返回示例:
{
"prepay_id":"*****",//预付费id
"code_url":"****"// 二维码地址
}
参数说明:
- appid 应用ID
- mch_id 商户号
- product_id 商品ID(trade_type=NATIVE时,此参数必传。此参数为二维码中包含的商品ID,商户自行定义。)
- key 商户平台设置的密钥key
- tradeno 商户订单号(商户系统内部订单号,要求32个字符内,只能是数字、大小写字母-|* 且在同一个商户号下唯一。)
- trade_type 交易类型。JSAPI -JSAPI支付; NATIVE -Native支付
- body 商品描述
- detail 商品详情
- openid 用户标识(trade_type=JSAPI时(即JSAPI支付),此参数必传,此参数为微信用户在商户对应appid下的唯一标识。)
- total_fee 标价金额 (订单总金额,单位为分)
- time_expire 交易结束时间 (订单失效时间,格式为yyyyMMddHHmmss,如2009年12月27日9点10分10秒表示为20091227091010。)
- notify_url 通知地址(异步接收微信支付结果通知的回调地址,通知url必须为外网可访问的url,不能携带参数。)
微信退款示例
- 将微信证书下载下来,下载路径:微信商户平台(pay.weixin.qq.com)-->账户中心-->账户设置-->API安全,
复制证书-pem格式(apiclient_cert.pem)和证书密钥pem格式(apiclient_key.pem)内容,作为参数字符串,需要使用``符号,不能使用""和''
示例:
//支付证书内容(此处是示例,不是完整证书内容,用户需填写完整证书内容)
const apiclient_cert = `-----BEGIN CERTIFICATE-----
QUQzOTc1NDk4NDZDMDFDM0U4RUJEMjANBgkqhkiG9w0BAQsFAAOCAQEAbdSJ60xe
9vLwa6r/dyQOArMH62HUAPpggaBoZ1CjL9l1rBEGujcHF1xxPRx0/DvJUwv/WQpM
g7uZZMeSj8ysL0L9vnjG6E2cd/5r/0+nuFOHWpHXClPaNfqzsTgHY2/+Ar33W
Uc2JoZhTOf7Diw==
-----END CERTIFICATE-----`;
//支付证书秘钥内容
const apiclient_key = `-----BEGIN PRIVATE KEY-----
NWAI/hX0QBlvCm6H9h4TFadfasdfr4HsMuPCIvKR7jJ2QKBgQD0b51kVTaH7iHm69Lz
GO9ygr0HK/uKn7hhWGkJShyqiAhFuTr2QQYJtcli8W9Om5TNQLOhSw1JV5
IWrC014DxlVUyMsrccy8Je4=
-----END PRIVATE KEY-----`;
const options = {
passphrase: mch_id,//商家id
key: apiclient_key,//支付证书内容
cert: apiclient_cert//支付证书秘钥内容
};
const rp = Models.api["request-promise"];
Models.api.console.info("发起退款请求");
let resData = await rp({
method:'POST',
url:url,
body:tData,
headers: {
'Content-Type': 'text/xml'
},
agentOptions: options
});
第三方模块
内置了如下nodejs模块:
- "request-promise",
- "crypto",
- "path",
- "underscore",
- "moment",
- "math",
- "voca",
- "jsonwebtoken",
- "@alicloud/pop-core",
- "cron",
- "axios",
- "prettier"
- "xml2js"
使用引用方法例如:
const rp = Models.api["request-promise"];
如想引用模块时,在初始化(Init)函数中添加,例如:
function Init(Models){
Models.install(['cron','request-promise']);
}
具体使用说明详见官方使用文档:
https://github.com/request/request-promise
https://github.com/node-modules/copy-to
http://nodejs.org/docs/latest/api/path.html
https://www.npmjs.com/package/node-math
https://github.com/auth0/node-jsonwebtoken#readme
https://github.com/aliyun/openapi-core-nodejs-sdk#readme
https://github.com/kelektiv/node-cron#readme
https://github.com/axios/axios
https://github.com/Leonidas-from-XIV/node-xml2js
内置管理后台
为方便用户使用,我们内置了管理后台模块,用户开启服务后可通过 "https://appid-dev.apicloud-saas.com/admin/" 在测试环境进行访问。 此功能需要全局配置开启session服务以及开通文件存储,请在全局配置进行相关操作。 管理后台详细说明见:https://gitlab.apicloud.com/apicloud/sentosa_doc/blob/master/docs/admin.md
预置模型
为了方便开发者快速入手,我们预置了demo,阿里短信,微信支付等,开发使用率相对较高的模型。可以在程序中直接引入模型库中的模型,引入后相当于引入了本地模型,可以基于引入模型进行二次开发。
如图所示:
异常处理及常见问题
异常处理
新版数据云提供了内置的异常信息处理对象gError(msg, code, statusCode)。
该对象的初始化参数分别为:
msg: 返回的错误信息。
code:返回的错误码,这个信息由开发者根据业务逻辑自行定义,如果不定义默认是 'UNKOWN'。
statusCode:返回的 http 错误状态码,如果不定义默认是400。
gError 定义如下:
class gError extends Error {
constructor(message = '', code = 'UNKNOWN', statusCode = 400, ...params) {
super(...params);
Error.captureStackTrace(this, mcmError);
this.message = message;
this.code = code;
this.statusCode = statusCode;
}
}
用户可以直接使用throw new gError() 来初始化错误信息对象,该对象所写的错误日志如果用户未进行处理将由系统自动记录到日志文件中;对于远程方法,该错误信息和错误码也会由框架自动返回到前端。
具体使用代码如下:
coffeeShop.userRate = async(rate,id)=> {
try{
Models.api.console.debug('id is ',id);
await coffeeShop.updateAll({"id":id},{"rate":rate});
return 'success'
}catch(e){
throw new gError(e,101,500);
}
}
这里使用gError把捕获的信息直接返给前端,同时该错误信息也会记录到用户日志信息中,可以在log中查看;其中101是用户自定义错误码(这里也可以是字符串),默认是'UNKONWN'; 500是http请求返回的状态码,默认是400.
常见问题
钩子函数循环调用问题,在数据访问的钩子函数中如果调用相关模型的与钩子相关的操作则容易引起死循环。如:在模型 Employee 中增加 access钩子函数,在该函数中近一步对Employee表做查询则会引起死循环。
如果服务等很长时间一直无法启动的时候,检查下自定义的MiddleWare函数中是否有next() 函数。没有的请添加进入。如果不需要,请清空。
日志打印:开发过程中以及后期维护的时候不可避免需要对日志进行处理,我们提供了内置的日志函数,方便大家直接调用。用户通过Models.api.console对象进行日志数据打印,该接口用法与js中的console类似,提供了不同的日志等级如下:debug、log、warn、error。不同等级的日志信息在控制台将以不同颜色进行展示。其中系统捕捉到的异常错误以及gError抛出的错误都会以error的错误等级打印信息。
具体使用方式如下:
- Models.api.console.debug(“打印调试信息”)
- Models.api.console.log(“打印日志信息”)
- Models.api.console.warn(“打印警告信息”)
- Models.api.console.error(“打印异常信息”)
如何判断系统重启成功:由于我们是云开发环境,依赖于云服务器重启完成测试代码的上线调试,可以在云函数开发界面通过底部的日志查看是否启动完成(通过顶部的启动日志按钮打开日志界面)。服务器启动成功后会打印一条信息 “Web server started”表示启动完成,这样就可以通过接口联调进行功能调试了。
使用include无法看到被关联的数据:请确保被关联的对象有该数据;如果同时使用了fields关键字,则外层的fields数组内需要包含本表的关联字段。
模型对应的方法不存在:注意模型的远程方法在调用时需要ModelName+‘s’,如模型名为team,则生成的条件查询总数的接口格式为“/api/teams/count”。
省市区县的行政区划信息:对于需要使用中国标准行政区划数据的情况,基于数据准确性和实时性等方面的考虑,建议前端使用第三方接口获取数据。如:腾讯位置服务(https://lbs.qq.com/service/webService/webServiceGuide/webServiceDistrict);或使用开源的前端插件(https://jquerywidget.com/jquery-citys/)。